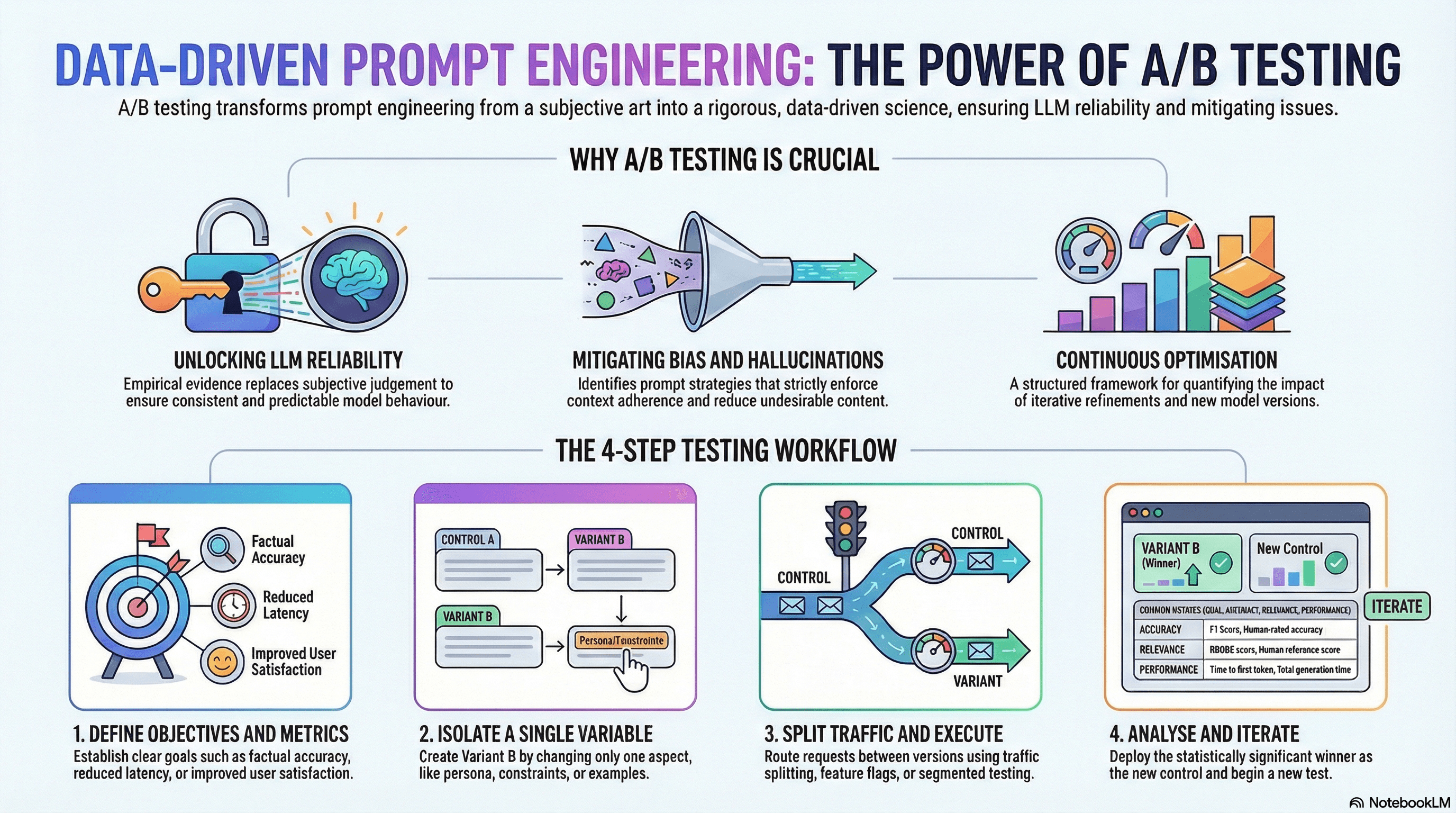
Why A/B Testing is Crucial for Prompt Engineering
Prompt A/B Testing: Turning Art into Data-Driven Science
LaikaTest
January 21, 2026
Why A/B Testing Prompts is Crucial for Robust Prompt Engineering
The advent of Large Language Models (LLMs) has revolutionized AI development, opening doors to unprecedented capabilities in natural language processing, content generation, and intelligent automation. However, harnessing the full potential of these powerful models isn't as simple as just asking a question. It requires sophisticated prompt engineering – the art and science of crafting inputs that guide an LLM to produce desired, high-quality, and reliable outputs.
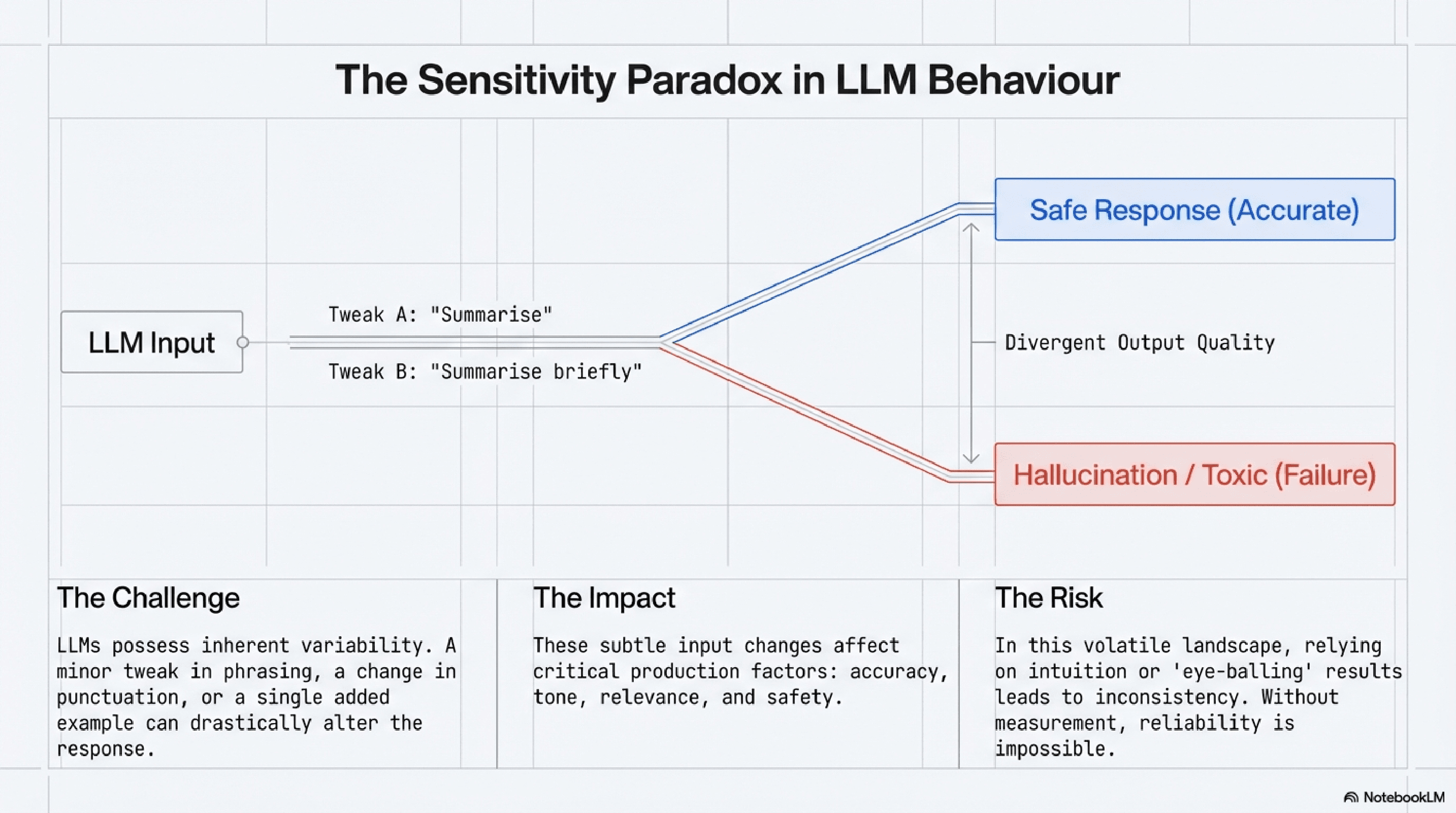
For AI engineers, the challenge lies in the inherent variability and sensitivity of LLMs. A minor tweak in a prompt, a different phrasing, or an added example can dramatically alter the model's response, impacting everything from accuracy and relevance to tone and safety. In this landscape, relying solely on intuition or anecdotal evidence is a recipe for inconsistency and unreliability. This is precisely why A/B testing is crucial for prompt engineering. It provides a rigorous, data-driven methodology to systematically evaluate prompt effectiveness, ensuring LLM reliability and driving continuous prompt optimization.
LLM Behaviour
What is A/B Testing in Prompt Engineering?
At its core, A/B testing, also known as split testing, is a method of comparing two versions of something – a "control" (A) and a "variant" (B) – to determine which performs better against a specific goal. When applied to prompts, A/B testing prompts involves presenting different versions of a prompt to an LLM (or a segment of users interacting with an LLM-powered application) and measuring the outcomes.
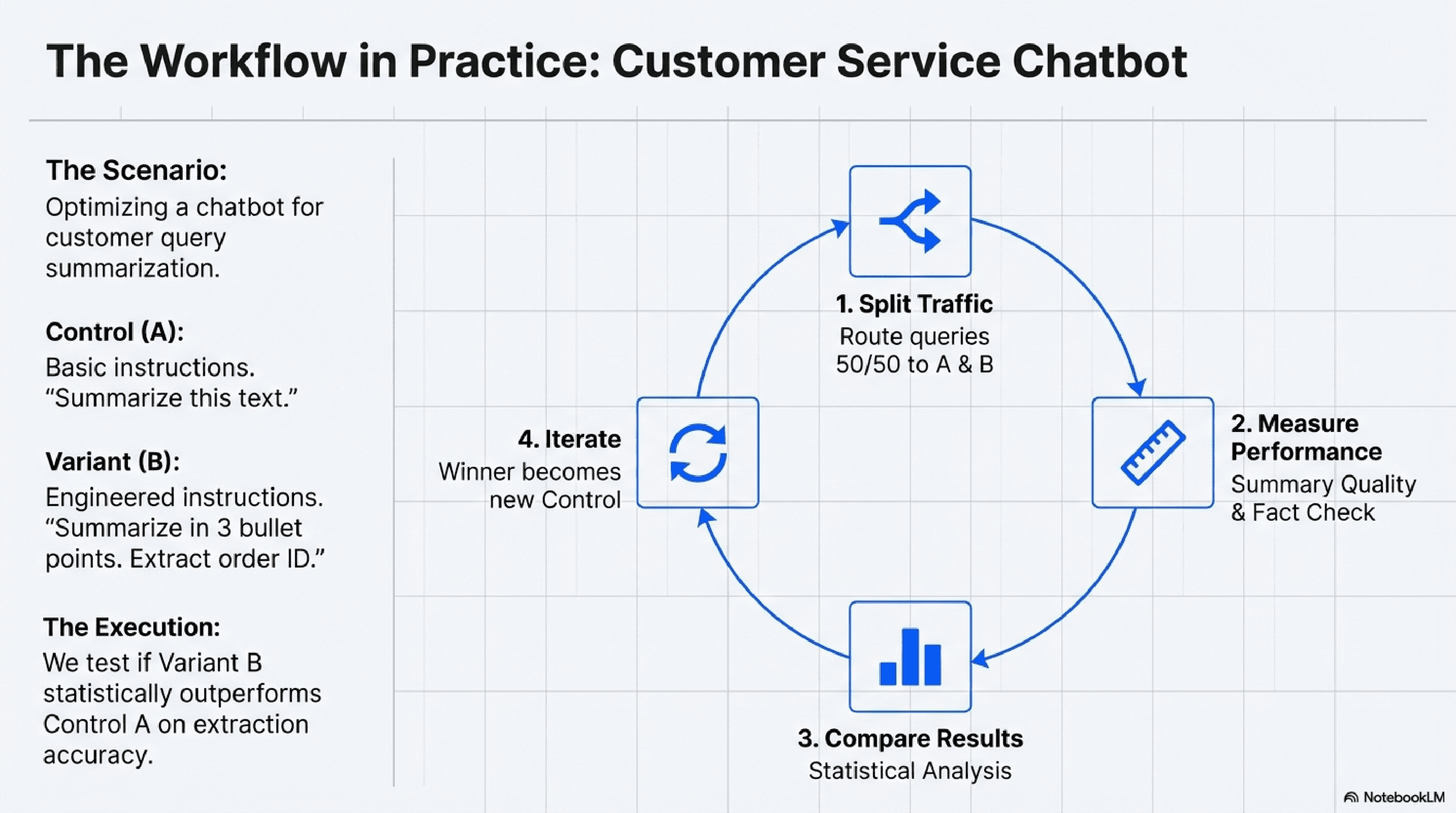
Imagine you're developing an LLM-powered customer service chatbot. You want to improve how it summarizes customer queries. You have an initial prompt (Prompt A). You then develop a new version (Prompt B) that includes more specific instructions on summarization length and key information to extract. An A/B test would involve:
1. Splitting Traffic: Directing a portion of incoming queries to be processed by the LLM using Prompt A, and another portion using Prompt B.
2. Measuring Performance: Collecting data on the quality of summaries generated by both prompts using predefined metrics (e.g., human evaluation scores, key information extraction accuracy, customer satisfaction ratings if applicable).
3. Comparing Results: Statistically analyzing the data to determine if Prompt B significantly outperforms Prompt A, or vice-versa.
Unlike traditional A/B testing in web design (where clicks or conversions are common metrics), prompt a b testing focuses on the quality and utility of the LLM's output. This requires careful consideration of evaluation metrics, often involving a blend of automated and human assessment, to truly understand which prompt variant delivers superior results for your specific application.

A/B Testing Prompt
Why A/B Testing Prompts is Crucial for Prompt Engineering Success
The question "Why is AB testing important?" resonates deeply within the realm of AI, particularly for those striving for excellence in prompt engineering. The answer lies in its ability to transform prompt development from an art to a data-informed science, ensuring robust and performant LLM applications.
Workflow in Practice
Unlocking True LLM Reliability
The outputs of LLMs can be notoriously sensitive to input variations. A slight change in wording, punctuation, or the inclusion of a single example can lead to dramatically different responses. Without a systematic way to compare these changes, achieving consistent and predictable behavior – the hallmark of LLM reliability – becomes a significant hurdle.
A/B testing prompts provides the empirical evidence needed to understand which prompt constructions consistently yield the desired output quality. It moves prompt selection beyond subjective judgment, enabling AI engineers to make data-backed decisions that enhance the robustness and dependability of their LLM integrations. This is why a b testing is crucial for prompt engineering brain trusts aiming to build production-ready AI systems.
Driving Continuous Prompt Optimization
Prompt engineering is an iterative process. It's rarely a "set it and forget it" endeavor. As models evolve, new use cases emerge, and performance requirements shift, prompts need continuous refinement. A/B testing prompts offers a structured framework for this ongoing prompt optimization.
By systematically testing hypotheses – such as whether adding a "chain of thought" instruction improves reasoning, or if a different persona yields more empathetic responses – engineers can quantify the impact of each change. This allows for incremental improvements, ensuring that the LLM is always performing at its peak. Whether you're aiming for higher accuracy, reduced latency, improved coherence, or better user engagement, A/B testing provides the measurable feedback loop necessary for continuous enhancement.

Crafting the Variant
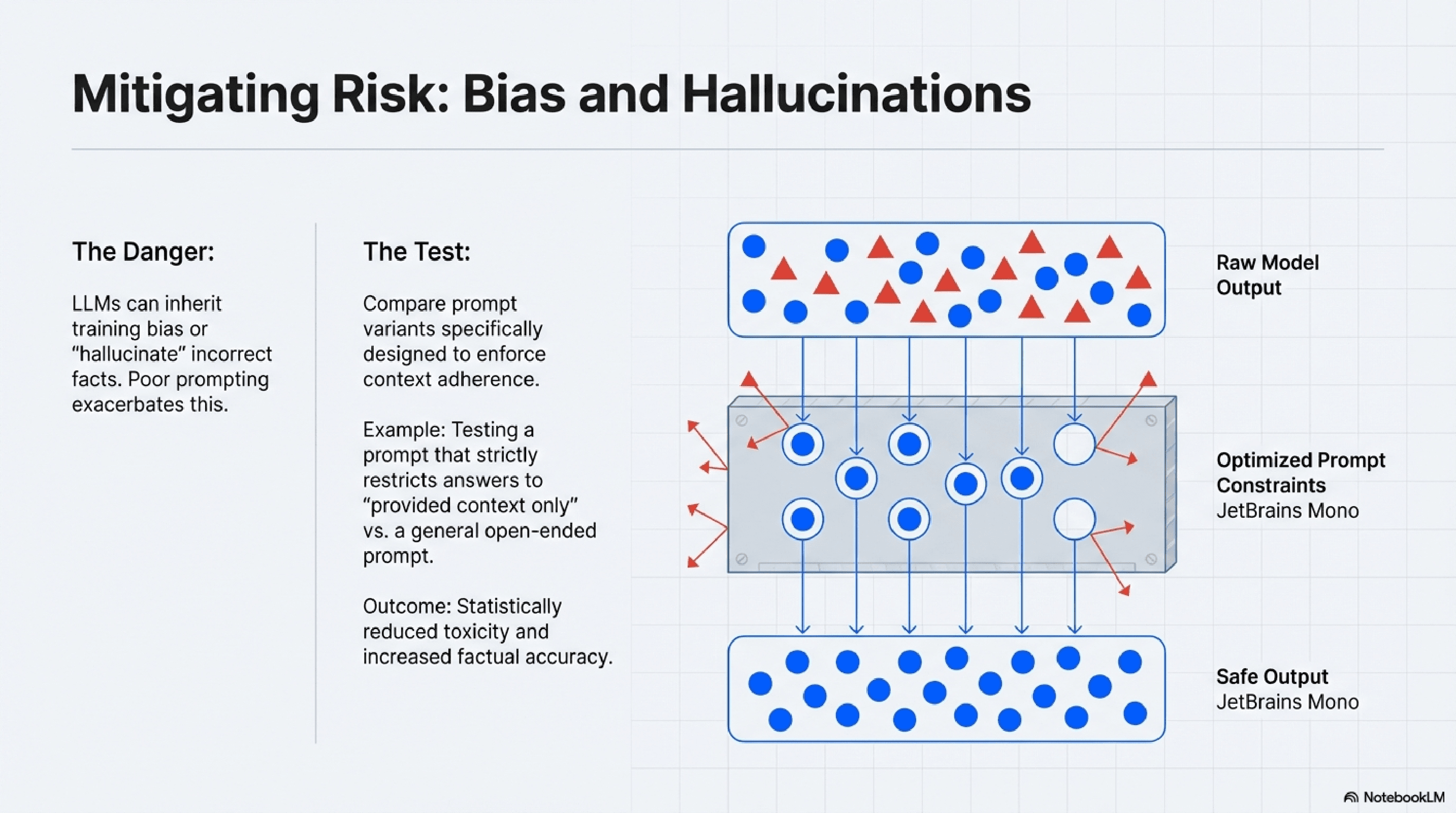
Mitigating Bias and Hallucinations
LLMs, while powerful, can inherit biases from their training data or "hallucinate" incorrect information. Different prompt strategies can either exacerbate or mitigate these issues. For instance, a prompt that asks for factual information without explicitly instructing the model to rely only on provided context might lead to more hallucinations than one that strictly enforces context adherence.
AI testing through A/B methodologies allows engineers to compare prompt variants specifically designed to reduce bias or minimize hallucinations. By measuring metrics related to factual accuracy, fairness, or the presence of undesirable content, A/B tests can identify prompts that lead to safer, more ethical, and more reliable AI outputs.
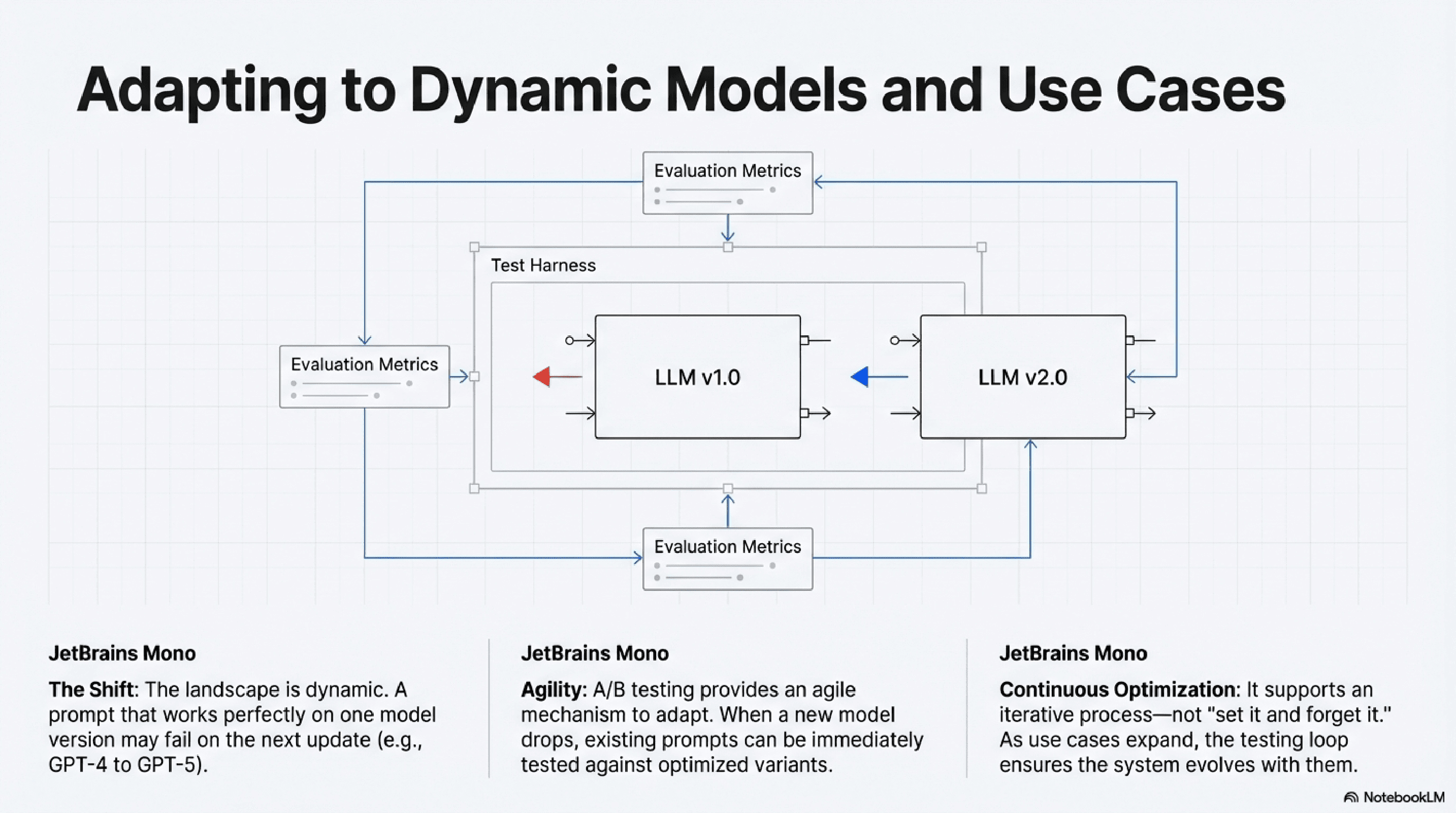
Adapting to Evolving Models and Use Cases
The LLM landscape is dynamic. New models are released frequently, and even existing models undergo updates. A prompt that worked perfectly with one version of an LLM might perform differently with another. Similarly, as your application's use cases expand, the demands on your prompts will change.
A/B testing prompts provides an agile mechanism to adapt to these shifts. When a new model version is deployed, or a new feature is introduced, you can quickly A/B test your existing prompts against optimized variants to ensure continued high performance. This proactive approach to AI testing is vital for maintaining competitive edge and user satisfaction.
Mitigating Risk
How to Perform Effective A/B Testing with Prompts
Implementing A/B testing prompts effectively requires a structured approach, moving beyond simple comparisons to sophisticated experimentation.
Defining Clear Objectives and Metrics
Before running any test, clearly articulate what you want to achieve and how you will measure success. Are you trying to:
Increase the accuracy of factual answers? (Metric: F1 score, human-rated accuracy)
Improve the relevance of generated content? (Metric: ROUGE score, human relevance score)
Reduce the toxicity or bias in responses? (Metric: Toxicity scores, human bias detection)
Lower the latency of response generation? (Metric: Time to first token, total generation time)
Enhance user satisfaction with a chatbot? (Metric: User ratings, task completion rates
For complex tasks, a combination of automated metrics and human evaluation is often necessary. Consider how LaikaTest prompt metadata or similar tracking mechanisms can help you log and analyze these metrics alongside your prompt versions.
Adapting to dynamic
Crafting Your Prompt Variants (A and B)
The key to a good A/B test is to isolate a single variable. When creating Prompt B (your variant), change only one significant aspect from Prompt A (your control). Examples include:
Instruction Style: Direct vs. conversational.
Persona: "You are a helpful assistant" vs. "You are an expert financial advisor."
Few-Shot Examples: Different or additional examples.
Constraints: Adding length limits, specific output formats (e.g., JSON).
Context Provision: How context is integrated and emphasized.
For instance, if you're working on a code generation task, you might test an MCP prompt example (Multi-Context Prompt) where one variant provides more structured context about the desired output framework versus another that relies on a more general description.

Crafting the variant
Setting Up Your Experiment Environment
For production systems, you'll need a mechanism to route user requests to different prompt versions. This could involve:
Traffic Splitting: Directing 50% of requests to Prompt A and 50% to Prompt B.
Segmented Testing: Targeting specific user groups with different prompts.
Feature Flags: Using a system like PostHog A/B testing (or similar internal tooling) to dynamically switch between prompts based on user or session IDs. For development and internal testing, robust LLM prompt management systems are essential. Tools that allow for version control, metadata tagging, and easy deployment of prompt variants streamline the experimentation process. Many teams use Prompt management GitHub repositories to track changes, but dedicated platforms offer more advanced features for experimentation and analysis.
Analyzing Results and Iterating
Once you've collected sufficient data, the next step is analysis. This involves:
Statistical Significance: Determine if the observed differences between Prompt A and Prompt B are statistically significant, meaning they are unlikely to have occurred by chance.
Drawing Conclusions: Based on the data, identify the winning prompt.
Implementing Changes: Deploy the superior prompt to all users or the relevant segment.
Iterating: The winning prompt becomes the new control (A), and you start the process again, testing a new hypothesis with a new variant (B). This continuous loop of testing, learning, and deploying is the essence of effective prompt optimization.
Beyond Basic A/B Testing: Advanced Considerations for Prompt Engineers
As your prompt engineering matures, you might explore more sophisticated AI testing techniques:
Multivariate Testing (MVT): Instead of changing one variable, MVT allows you to test multiple variables simultaneously (e.g., different instruction styles and different few-shot examples), identifying optimal combinations.
Contextual A/B Testing: Tailoring prompt variants based on specific user segments, historical interactions, or real-time context to deliver hyper-personalized and effective LLM responses.
Automated Evaluation Pipelines: Integrating automated metrics (like ROUGE, BLEU, or custom classifiers) into your CI/CD pipeline to provide continuous feedback on prompt performance, especially valuable for LangGraph prompt management where complex chains of prompts are involved.
Canary Deployments and Rollbacks: Gradually rolling out new prompt versions to a small subset of users before full deployment, allowing for quick rollbacks if unexpected issues arise.
Robust prompt management systems that integrate version control, performance monitoring, and experimentation capabilities are becoming indispensable for AI engineers. These platforms facilitate not only the execution of A/B tests but also the crucial tracking of Langfuse prompt metadata and other key performance indicators across different prompt versions.
Conclusion
In the rapidly evolving world of LLMs, prompt engineering is no longer a peripheral task but a core discipline for AI engineers. To move beyond guesswork and achieve truly reliable, performant, and continuously optimized LLM applications, A/B testing prompts is not just beneficial – it is absolutely crucial.
Tags
#A/B Testing#Prompt Management#Prompt Engineering