What is A/B Testing?
The Framework That Makes AI Actually Work in Production
Shlok Arora
November 17, 2025

The A/B testing, at its core, is a controlled experiment comparing two versions of something to determine which performs better. In traditional software, you might test two button colors or two headline variations. In AI applications, you're comparing different prompts, model configurations, or entire agent architectures.
The concept is simple: split your traffic between variant A (control) and variant B (treatment), measure outcomes, and let statistical significance tell you which version actually works better. No guesswork. No assumptions. Just data.
The Uncomfortable Truth: AI Is Fundamentally Unreliable
Let's address the elephant in the room. AI applications, particularly those built on large language models, are probabilistic by nature. Unlike traditional deterministic software where 2 + 2 always equals 4, LLMs operate in a world of probabilities, context windows, and statistical patterns.
Recent research paints a stark picture:
The hallucination crisis is getting worse, not better. Studies from 2025 show that newer thinking models like GPT-o3 and DeepSeek-R1 are actually hallucinating more than their predecessors. While they generate more accurate claims overall, they also produce significantly more false outputs. According to industry reports, AI hallucinations make up between 3-10% of all LLM responses and that's in general use cases, not specialized domains where the problem compounds.
Real-world consequences are mounting. In February 2024, Air Canada was legally ordered to honor a bereavement fare that their AI chatbot completely fabricated. A New York lawyer faced sanctions in Mata v. Avianca for submitting legal briefs citing cases that ChatGPT invented. A University of Mississippi study found that 47% of AI-generated citations from students contained incorrect titles, dates, authors, or a combination thereof.
The problem is structural, not solvable. OpenAI's own research from September 2025 reveals why: next-token prediction training objectives and common benchmarks reward confident guessing over calibrated uncertainty. Models learn to "bluff" rather than admit ignorance. Learning theory research confirms that LLMs cannot learn all computable functions hallucinations are mathematically inevitable when using these models as general problem solvers.
But here's the thing: this doesn't mean AI is useless. It means we need to treat it differently than traditional software.
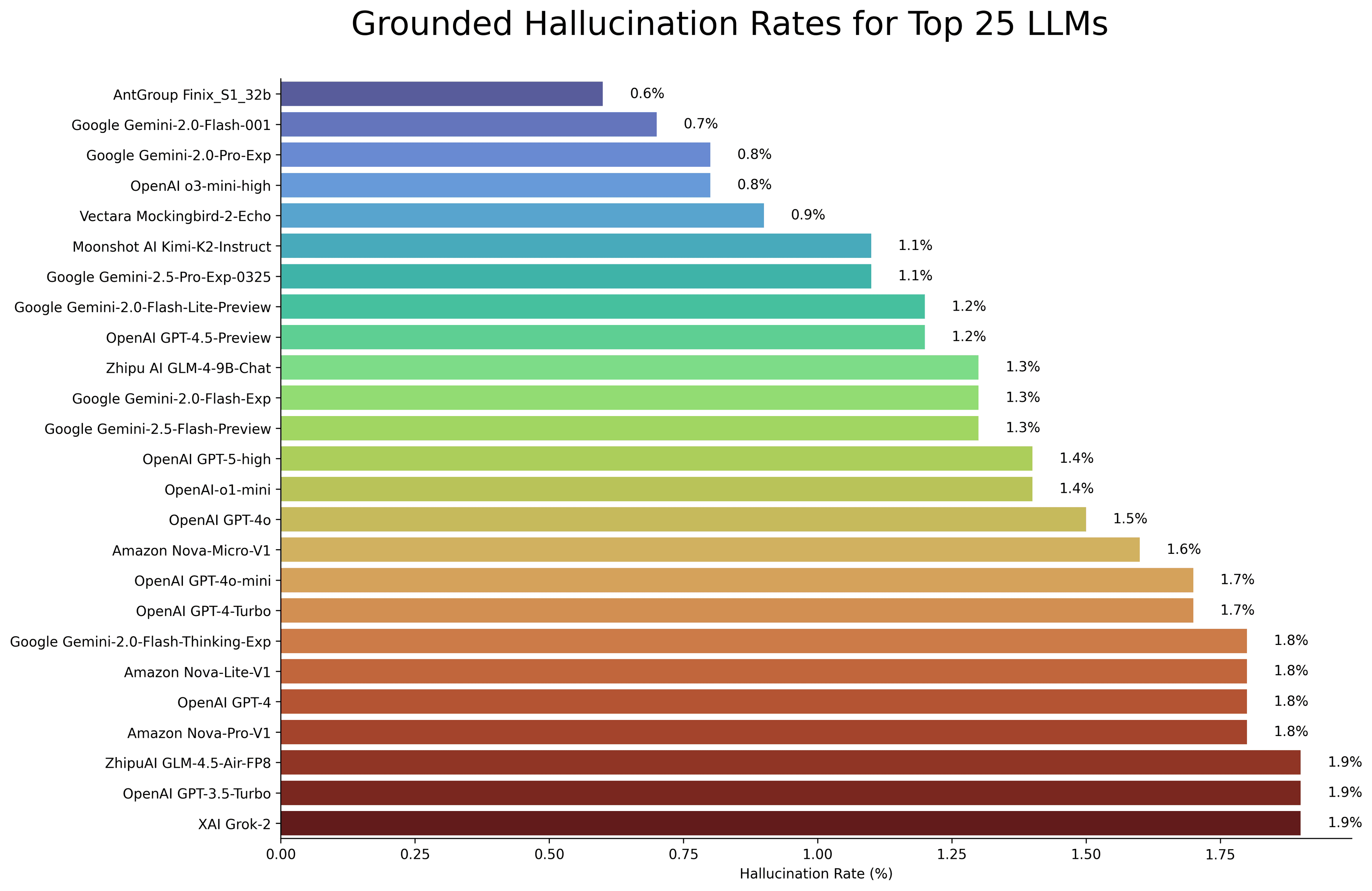
Hallucination Rates
Hallucinations: The Silent Killer of AI Products
Hallucinations aren't just academic curiosities they're production incidents waiting to happen. When your AI agent confidently fabricates database schema, invents API endpoints, or hallucinates user permissions, you don't just have incorrect outputs. You have security vulnerabilities, broken user experiences, and eroded trust.
The insidious part? Hallucinations often sound plausible. LLMs are trained to produce fluent, coherent text. They'll confidently cite non-existent studies, reference fabricated documentation, and construct elaborate reasoning chains built on false premises. Without systematic validation, you won't catch them until they're in production.
A recent survey found that 89% of ML engineers report their LLMs exhibit signs of hallucinations. This isn't a niche problem affecting cutting-edge research it's the baseline reality of working with language models.
Why You Can't Trust Your Prompts (Even When They "Work")
Here's a common scenario: You spend hours crafting the perfect prompt. You test it manually with a few examples. It works beautifully. You ship it to production. Two weeks later, users are reporting bizarre outputs. What happened? Prompt engineering is not a deterministic science. The same prompt can produce wildly different results depending on:
- Context window position: Whether relevant information appears early or late in the prompt
- Temperature and sampling settings: Subtle configuration changes cascade into behavioral shifts
- Model version drift: Even the "same" model gets updated, changing behavior silently
- Edge cases you didn't test: Real user inputs rarely match your hand-crafted test cases
- Compound interactions: When chaining multiple LLM calls (common in AI agents), unpredictability compounds exponentially
The Langchain ecosystem and modern AI agent frameworks have made it trivial to chain multiple LLM calls, use retrieval-augmented generation, and build sophisticated multi-step reasoning systems. This is powerful but it also means your system has dozens of probabilistic decision points, each one a potential source of unexpected behavior. You can't debug what you can't measure. And you can't measure what you don't systematically test.

How AB Test Prompts for Consistent AI Output
How A/B Testing Makes AI Reliable
This is where systematic experimentation transforms everything. A/B testing gives you the quantitative foundation to move from "this prompt feels better" to "this prompt improves task completion by 23% with 95% confidence."
Here's how it works in practice:
1. Baseline Establishment
Start by measuring your current prompt's performance. What's the success rate? Average latency? User satisfaction score? You need objective metrics, not vibes.
2. Hypothesis-Driven Iteration
Create variant prompts with specific hypotheses:
Adding structured output formatting will reduce parsing errors
Explicitly requesting citations will decrease hallucination rates
Breaking complex tasks into sequential steps will improve reasoning accuracy
3. Traffic Splitting & Measurement
Route a percentage of traffic to each variant. Track outcomes: task success, error rates, user ratings, and hallucination frequency (if you're using guardrails to
detect them).
4. Statistical Validation
Run the experiment until you hit statistical significance. No more shipping changes based on 3 manual tests. You need confidence intervals, p-values, and sample
sizes large enough to detect real effects.
5. Continuous Optimization
This isn't a one-time exercise. AI models update. User behavior shifts. Context changes. The winning prompt from last month might be obsolete today. A/B testing
becomes your continuous feedback loop.
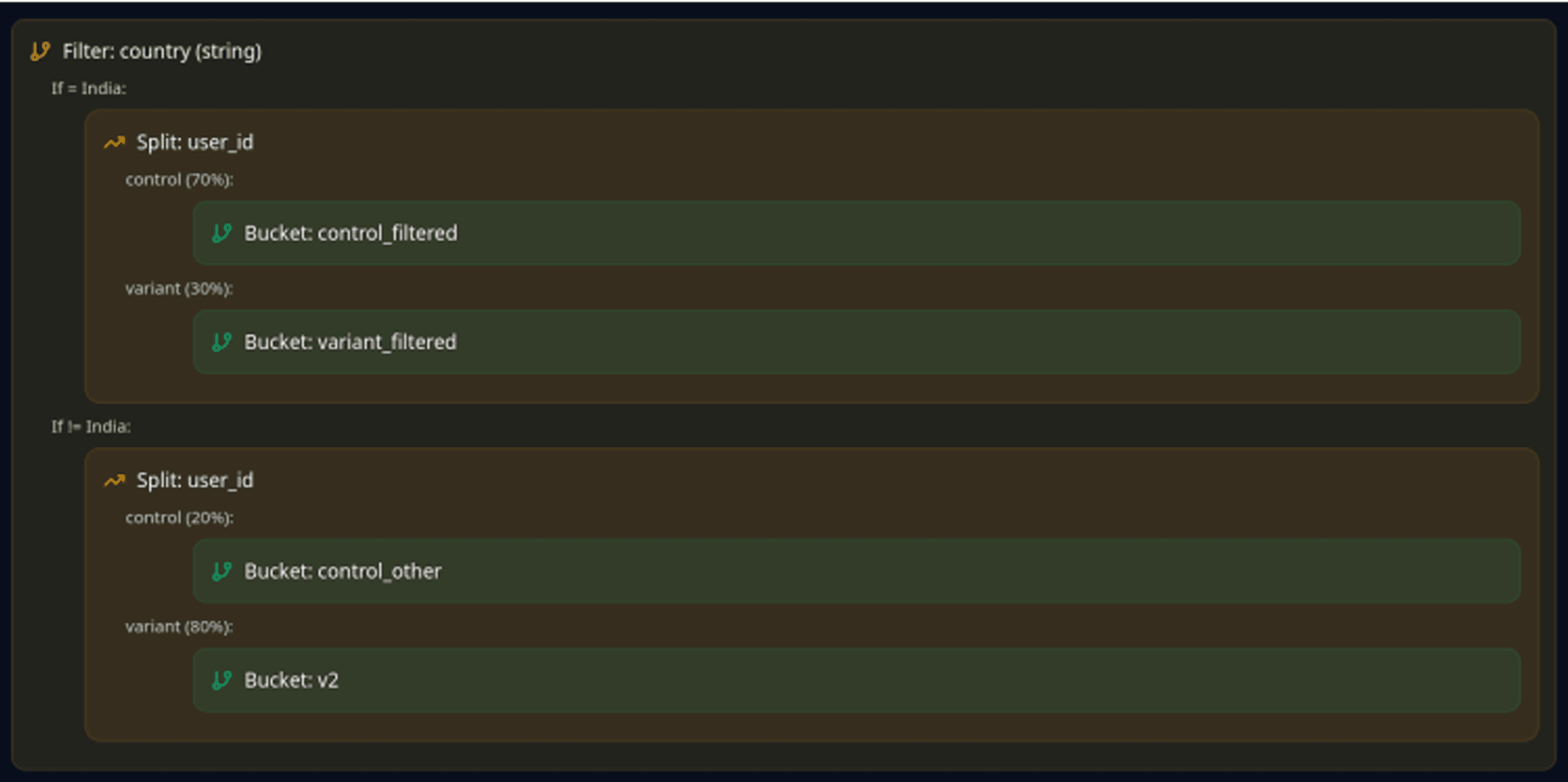
How LaikaTest Solves This Problem
How LaikaTest Solves This Problem
Building this infrastructure yourself is possible but painful. You need experiment management, traffic splitting, metrics collection, statistical analysis, and prompt versioning. Most teams end up with duct-taped solutions that break under production load.
That's exactly why we built LaikaTest.
1-Line Integration
One function call. That's it. Your prompts are now part of a managed experimentation platform.
All Prompts in One Place
No more prompts scattered across codebase files, environment variables, and Google Docs. Centralized prompt management means your entire team can see, version, and experiment with prompts without touching code.
Quantification That Actually Works
You get real metrics: success rates, statistical significance, confidence intervals,accuracy." and intervals, and time-series analytics. You know with mathematical certainty whether your AI is working or just lucky.
Guardrails That Keep AI Honest
Our guardrail system lets you define constraints: "No hallucinated citations." "Always include reasoning steps." "Output must be valid JSON." When variants violate guardrails, you catch it in testing, not in production.
Quick to Set Up, Easy to Use
We learned from the experiments with the v3 feature that developers don't want complex dashboards; they want answers. LaikaTest gives you the depth you need for rigorous testing with the simplicity you want for daily use.
The Bigger Picture: Making AIpossible butAIliable
AI by nature is unreliable. Models hallucinate. Prompts drift. Edge cases multiply. But unreliable testing? testing?ting?testing?testing?unusable. Traditional software engineering taught us to handle unpredictability: version control, automated testing, monitoring, and gradual rollouts. We need to apply those same principles to AI but adapted for probabilistic systems.
A/B testing your prompts isn't about perfection. It's about measurable improvement. It's about knowing when you've made things better and knowing when you've accidentally made things worse before users do.
Our mission at LaikaTest is simple: make AI more reliable.
Not by pretending hallucinations don't exist. Not by hoping your prompts work. But by giving you the tools to measure, experiment, and validate systematically. Because in a world where AI is eating software, reliability isn't optional; it's the difference between a product that works and a liability you're shipping to production.
Ready to make your AI applications reliable? Start A/B testing your prompts with LaikaTest's 1-line integration. Your users will thank you.
Tags
#AI Reliability#A/B Testing#Prompt Engineering#LLM Hallucinations#AI Evaluation#LaikaTest#AI in Production