Guardrails vs Moderation vs Evals: What’s the Difference?
A clear guide to how guardrails, moderation, and evals work together to build safe, reliable AI systems.
Naman Arora
November 24, 2025

You’re on a tight deadline to ship an AI‑powered chatbot. After weeks of building and testing, the demo goes live and boom! Your bot confidently suggests a user to “just fake their tax returns.” Cue frantic scrambling, PR damage control and sleepless nights. Sound familiar? We’ve all been there watching an LLM behave unpredictably just when it matters the most. My wake‑up call came while working on a mental‑health chatbot. One weekend a user reported that the bot responded to a benign question with a harmful remark. We had some logging and offline tests but nothing to stop the bad output from reaching them. That’s when I dove deep into guardrails, content moderation and evals, and realized that they are not the same thing. In this article I’ll walk through the differences, share real‑world examples and help you decide when to use which.
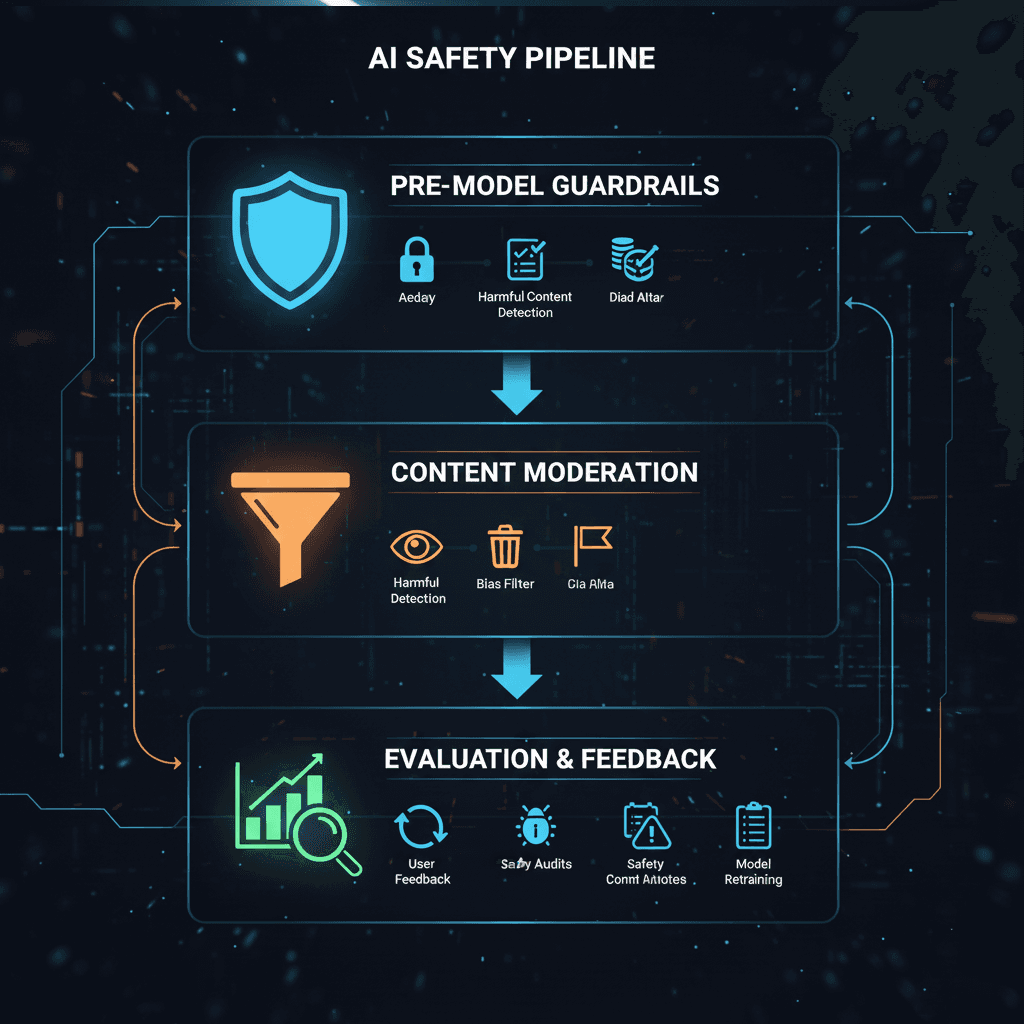
Guardrails: building the seatbelts of AI systems
Think of guardrails as the seatbelts and crash barriers on the highway: they don’t guarantee you’ll never crash, but they dramatically reduce the chance of catastrophes. Guardrails are inline safety checks that sit directly in the request/response path. They validate inputs before a model sees them (pre‑model guardrails) or outputs before they reach the user (post‑model guardrails).
Guardrails need to be:
Fast and deterministic: they typically have only a few milliseconds of latency budget. That means using simple rules, schemas or lightweight classifiers rather than slow LLM judges.
Targeted at clear‑cut, high‑impact failures: like personally identifiable information (PII) leaks, profanity, prompt injection, SQL injection or invalid JSON. A pre‑model guardrail might block any prompt containing a credit card number, while a post‑model guardrail could redact phone numbers in the response.
Versioned and monitored: because they affect user‑visible behavior, false positives are treated as production bugs and teams monitor trigger rates.
Real‑world examples
Finance: In an algorithmic trading assistant, a pre‑model guardrail might reject orders when market volatility exceeds a threshold; a post‑model guardrail can block recommendations that would breach a portfolio’s risk exposure. Evals then track accuracy and drift over time.
Supply chain logistics: A fleet management bot can use guardrails to reject route requests through restricted zones and enforce maximum daily driving hours. Separate evals measure fuel‑efficiency and on‑time delivery.
Retail reviews: Before summarizing customer feedback, pre‑model guardrails redact PII and filter disallowed commands. Post‑model guardrails ensure no competitor names appear in the public review.
When guardrails shine
Use guardrails whenever the stakes are high and you can define a clear “unsafe” condition. They are indispensable for customer‑facing agents, regulated industries (healthcare, finance) or any application where a single toxic output could cause harm. However, don’t expect them to detect subtle factual errors or bias; that’s where evals come in.
Moderation: classifying content into safe and unsafe
Content moderation predates the LLM era. Social platforms use classifiers to detect hate speech, violence or sexual content after it is posted. With generative AI, moderation needs to occur earlier: instead of policing user uploads, teams must intercept toxic or biased content generated by the model. In other words, moderation becomes part of the model layer.
Modern moderation systems use dedicated classification models such as OpenAI’s Moderation endpoint. These models take a message or response and return probabilities across categories like hate, sexual content, self‑harm or violence. Developers then decide whether to block, redirect or allow based on thresholds.
Why moderation is distinct from guardrails
Category‑focused: Moderation focuses on labeling content according to a safety taxonomy. For example, Llama Guard can label a prompt as “safe,” “violent,” or “elections,” and route accordingly.
Not necessarily deterministic: The models can return probabilities and may misclassify due to bias.
Reactive and policy‑driven: Traditional moderation was reactive content got flagged after posting. With GenAI, moderation must shift left to intercept outputs before the user sees them. Tools like Lakera Guard implement policy‑driven moderation that filters outputs in real time.
Limitations
Content moderation alone isn’t enough. Attackers can craft prompts that evade keyword filters or embed instructions in seemingly benign text. Moderation models themselves can reflect biases; OpenAI’s moderation endpoint, for instance, returns a score for each category and developers must choose thresholds. That’s why moderation should be part of a layered defense combined with guardrails and evals.
Evals measuring quality and closing the feedback loop
Evals (evaluations) are how you answer the question: “Is my AI working well?” They are systematic, often automated tests that measure quality and track improvements over time. Unlike guardrails, evals don’t block responses; they inform you whether a model is hallucinating, biased or drifting.
Evaluation methods fall into two main camps:
Reference‑based evals compare model outputs to ground truth answers. Metrics include exact match, word overlap, BLEU, ROUGE, embedding similarity and LLM‑as‑judge scoring. These are common when you have labelled data.
Reference‑free evals assess outputs directly via rules, regular expressions, text statistics or LLM‑based judges. For example, you might check whether a summarization contains all key facts or whether a code snippet compiles.
Evals can be run in batch on large datasets or continuously in production, feeding dashboards and triggering alerts. Because they can be computationally heavy especially when using LLM‑as‑judge evals are typically asynchronous.
Examples of evals in practice
Question‑answering: Evaluate your assistant’s answers on factual accuracy, completeness and tone. Use LLM‑as‑judge scoring when human labelling is impractical.
Summarisation: Compare generated summaries to reference summaries using ROUGE or ask an LLM judge to rate coherence.
Agentic workflows: Evaluate the success rate of multi‑step plans and tool calls. For a trading bot, you might test how well it meets compliance rules across diverse scenarios.
When to prioritise evals
Batch evals are invaluable during development. They help you choose the right model, prompt or retrieval strategy and detect regressions when you make changes. In production, they serve as smoke alarms, catching drops in quality or drift over time. However, you shouldn’t rely on them for real‑time protection. Combine them with guardrails and moderation for full coverage.

B3
Putting it all together
So when should you use guardrails, moderation or evals? The answer is almost always all three, but their roles vary across the lifecycle:
During development: Start with batch evals to benchmark models and refine prompts. Use synthetic and real test cases to understand hallucination rates, bias and robustness. Based on eval findings, design targeted guardrails and moderation policies.
Before deployment: Implement pre‑model and post‑model guardrails to block high‑impact failures (PII leaks, code injection). Add moderation models to classify content into safe/unsafe categories.
During deployment: Use real‑time guardrails as the first line of defence. Evaluate a sample of interactions continuously through background evals to monitor drift and calibrate thresholds. When evals reveal new failure modes, update guardrails and moderation policies.
This layered approach mirrors how modern enterprises run AI agents: immediate safety nets catch obvious failures, while deeper evaluations drive continuous improvement.

B1
Deploy guardrails in 60 seconds with LaikaTest
If implementing all this sounds like a lot of work, that’s because it is. At LaikaTest we’ve spent countless hours building an experimentation platform that simplifies it. Our guardrails module lets you set up pre‑model and post‑model filters, integrate moderation models and schedule evals all in under a minute. Want to block PII leaks? Just toggle a switch. Need to test a new prompt? Our A/B testing and eval dashboards show you how it performs across real user data. We believe that experimentation is the only way to tame AI unpredictability, and we built LaikaTest so you don’t have to stitch together half a dozen tools.
B2
References
Hamel Husain. Q: What’s the difference between guardrails & evaluators? hamel.dev.
Weaviate. Evals and Guardrails in Enterprise workflows. weaviate.io
McKinsey & Company. What are AI guardrails? mckinsey.commckinsey.com.
Confident AI. LLM Guardrails for Data Leakage, Prompt Injection, and More confident-ai.comconfident-ai.com.
AVID. Guardrails on Large Language Models, Part 4: Content Moderation avidml.org.
Lakera. What Is Content Moderation for GenAI? lakera.ailakera.ai.
Giskard. Real‑Time Guardrails vs Batch LLM Evaluations: A Comprehensive AI Testing Strategy giskard.aigiskard.ai.
Evidently AI. LLM evaluation metrics and methods, explained simply
Tags
#LLM Guardrails#GenAI Safety#AI Risk Management#AI Governance#Responsible AI#Guardrails vs Moderation