Tutorial: Implementing Prompt A/B Tests in Production
A technical roadmap for systematic, data-driven prompt experimentation
LaikaTest
January 21, 2026
Mastering Prompt A/B Testing in Production: A Practical Guide for LLM Optimization
The rapid evolution of Large Language Models (LLMs) has transformed how we build intelligent applications. From customer service chatbots to sophisticated content generation tools, LLMs are becoming central to many production systems. However, the performance of these models is profoundly influenced by the prompts they receive. Slight variations in wording, structure, or context can lead to dramatically different, and often unpredictable, outputs. This inherent variability makes reliable LLM production testing a critical, yet often overlooked, challenge.
LLM Production Optimization
For platform and infrastructure engineers tasked with maintaining robust, high-performing LLM-powered applications, the question isn't if you need to optimize prompts, but how. The answer lies in systematic experimentation: specifically, implementing robust prompt A/B testing production frameworks. This practical guide will walk you through the essential components, steps, and best practices for bringing data-driven prompt optimization to your production environment.
Why Prompt A/B Testing is Indispensable for LLM Production Success
Integrating LLMs into production systems introduces a new layer of complexity. Unlike traditional software, where deterministic logic governs outcomes, LLMs operate with a degree of probabilistic reasoning. The "prompt" acts as the primary interface, guiding the model's behavior. Crafting effective prompts is more art than science, making continuous prompt evaluation and refinement essential.
Infrastructure for Robust Applications
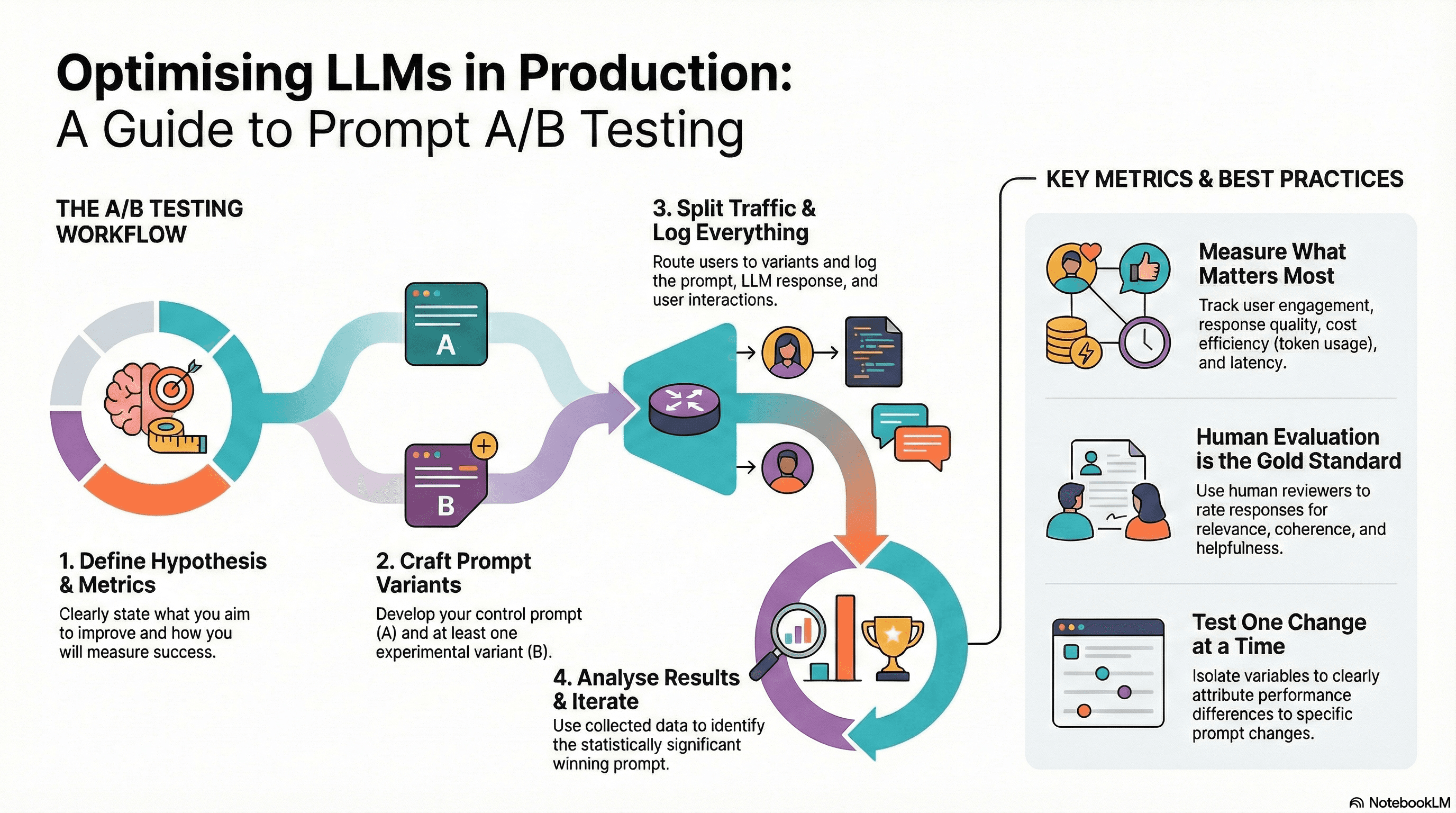
A structured A/B test tutorial approach for prompts offers several compelling benefits:
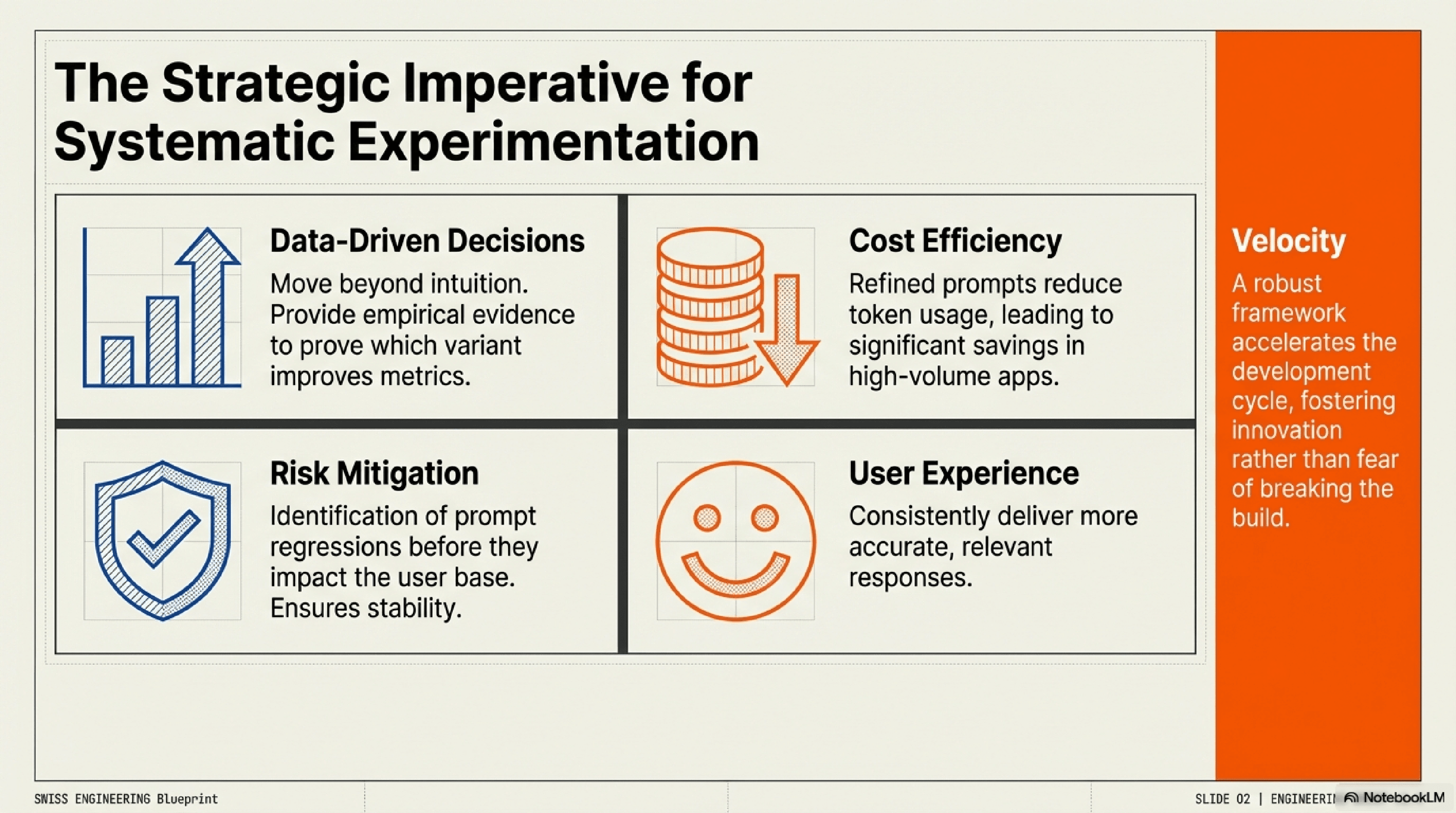
Data-Driven Decisions: Move beyond intuition. A/B tests provide empirical evidence to prove which prompt variations genuinely improve performance metrics, leading to more informed decisions.
Enhanced User Experience: By optimizing prompts, you can ensure LLMs consistently deliver more accurate, relevant, and helpful responses, directly improving the end-user experience.
Cost Efficiency: Subtly refined prompts can reduce token usage by making requests more concise or guiding the model more efficiently, leading to significant cost savings in high-volume applications.
Faster Iteration and Innovation:A robust testing framework enables rapid iteration on prompt ideas, accelerating the development cycle and fostering innovation in your LLM applications.
Risk Mitigation: Identify and mitigate prompt regressions before they impact a large user base, ensuring the stability and reliability of your LLM services.
Infrastructure for Robust Applications
The Architecture of an Effective Prompt A/B Testing System
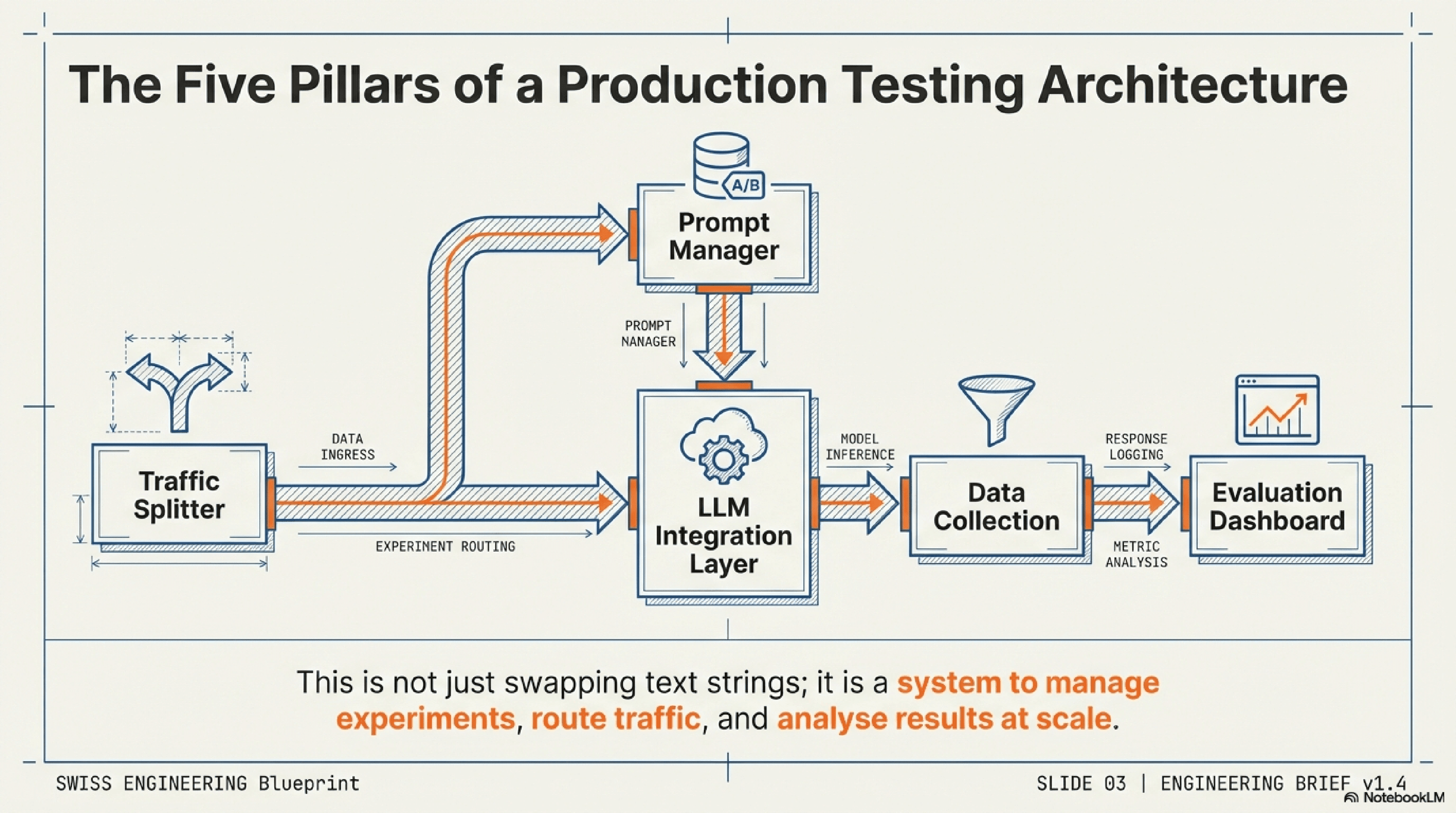
To successfully implement prompt A/B testing production, you need a well-designed architecture that integrates seamlessly with your existing infrastructure. This isn't just about swapping out one prompt for another; it's about building a system that can manage experiments, route traffic, collect data, and analyze results at scale.
System Architecture Overview
Key Components for Robust LLM Production Testing
A comprehensive prompt A/B testing system typically involves the following core components:
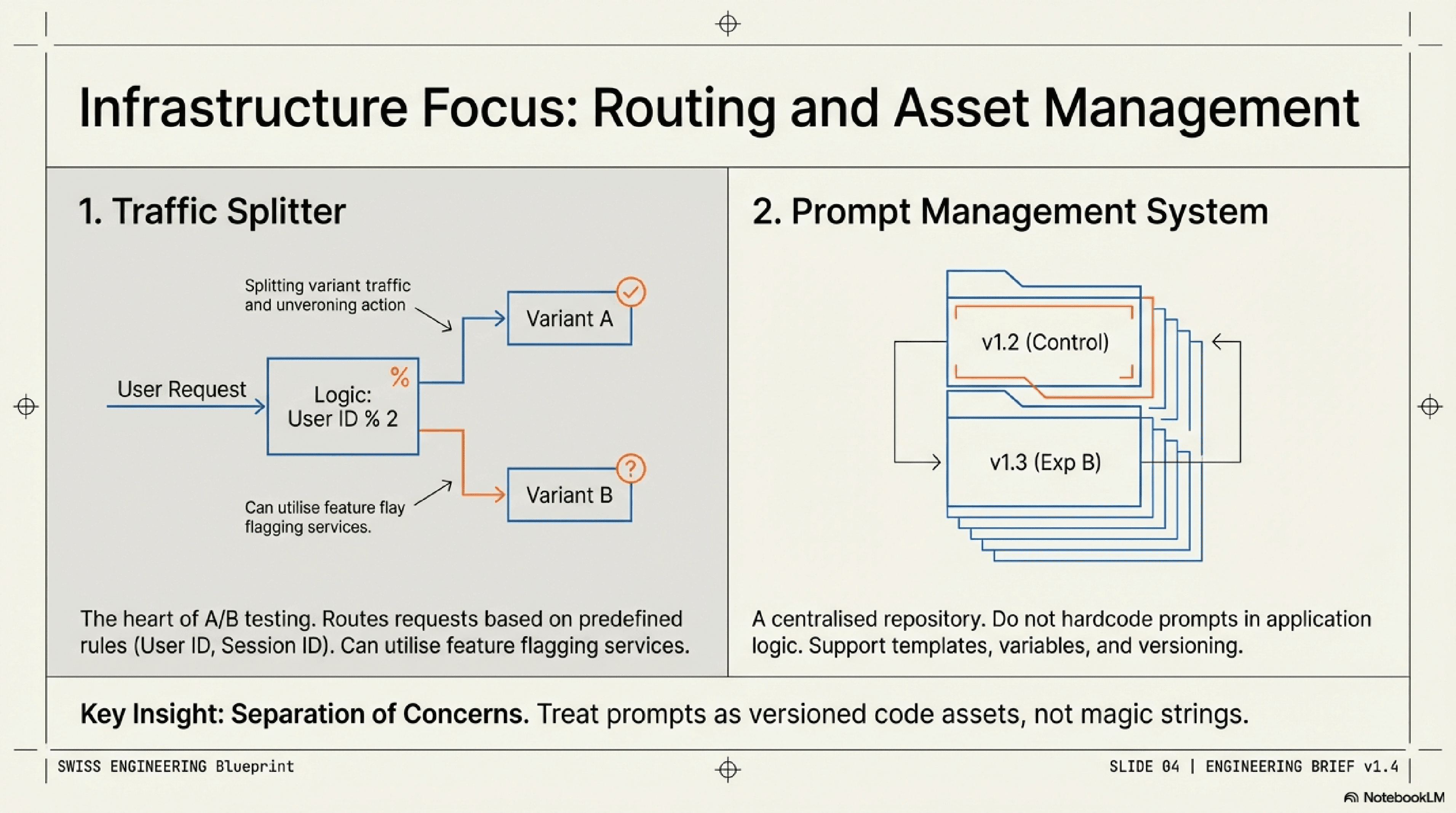
Traffic Splitting & Prompt Repositories
Traffic Splitter/Experimentation Platform: This is the heart of your A/B testing. It's responsible for routing incoming requests to different prompt variants based on predefined rules (e.g., user ID, session ID, random assignment). Existing feature flagging services or dedicated experimentation platforms are ideal for this.
Prompt Management System: A centralized repository for storing, versioning, and managing all your prompts. This system should allow you to define prompt templates, variables, and different versions (A, B, C, etc.) for experimentation.
LLM Integration Layer: The component that interfaces directly with your LLM provider (e.g., OpenAI API, Hugging Face, internal models). It receives the chosen prompt variant from the traffic splitter, sends it to the LLM, and captures the response.
Data Collection & Analytics Pipeline: Critical for logging every relevant event: the prompt variant used, the LLM's response, user interactions with that response (e.g., thumbs up/down, edits, follow-up questions, task completion), and any associated metadata (latency, token usage). This data feeds into your analytics dashboard.
Evaluation Metrics Dashboard: A visualization and reporting tool that presents the performance of each prompt variant against your defined metrics. This is where you identify winning prompts.
Designing Your Experimentation Framework for Prompt Evaluation
Your experimentation framework should be flexible and scalable. Think about how you'll define user segments, how long experiments will run, and how results will be aggregated. The goal is to isolate the impact of prompt changes from other variables, ensuring meaningful prompt evaluation. This often means ensuring consistent LLM models, parameters, and application logic across all variants, with only the prompt being the differentiating factor.
LLM Integration & Data Pipelines
Tutorial: Implementing Prompt A/B Tests in Production
Now, let's dive into the practical steps for setting up your prompt A/B testing production pipeline. This A/B test tutorial focuses on the logical flow, which can be adapted to various technical stacks.
Step-by-Step Guide to Setting Up Your First Prompt A/B Test
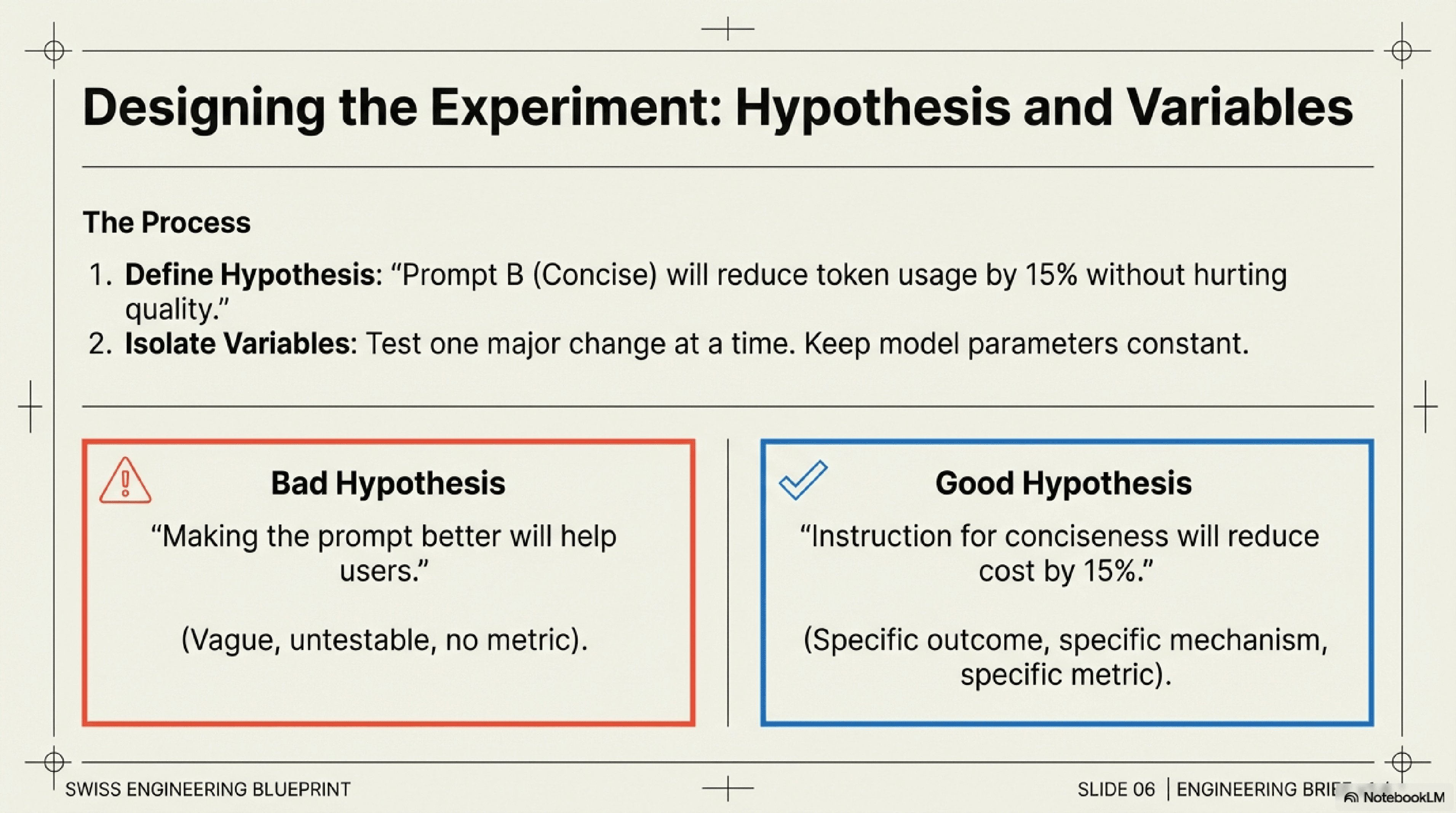
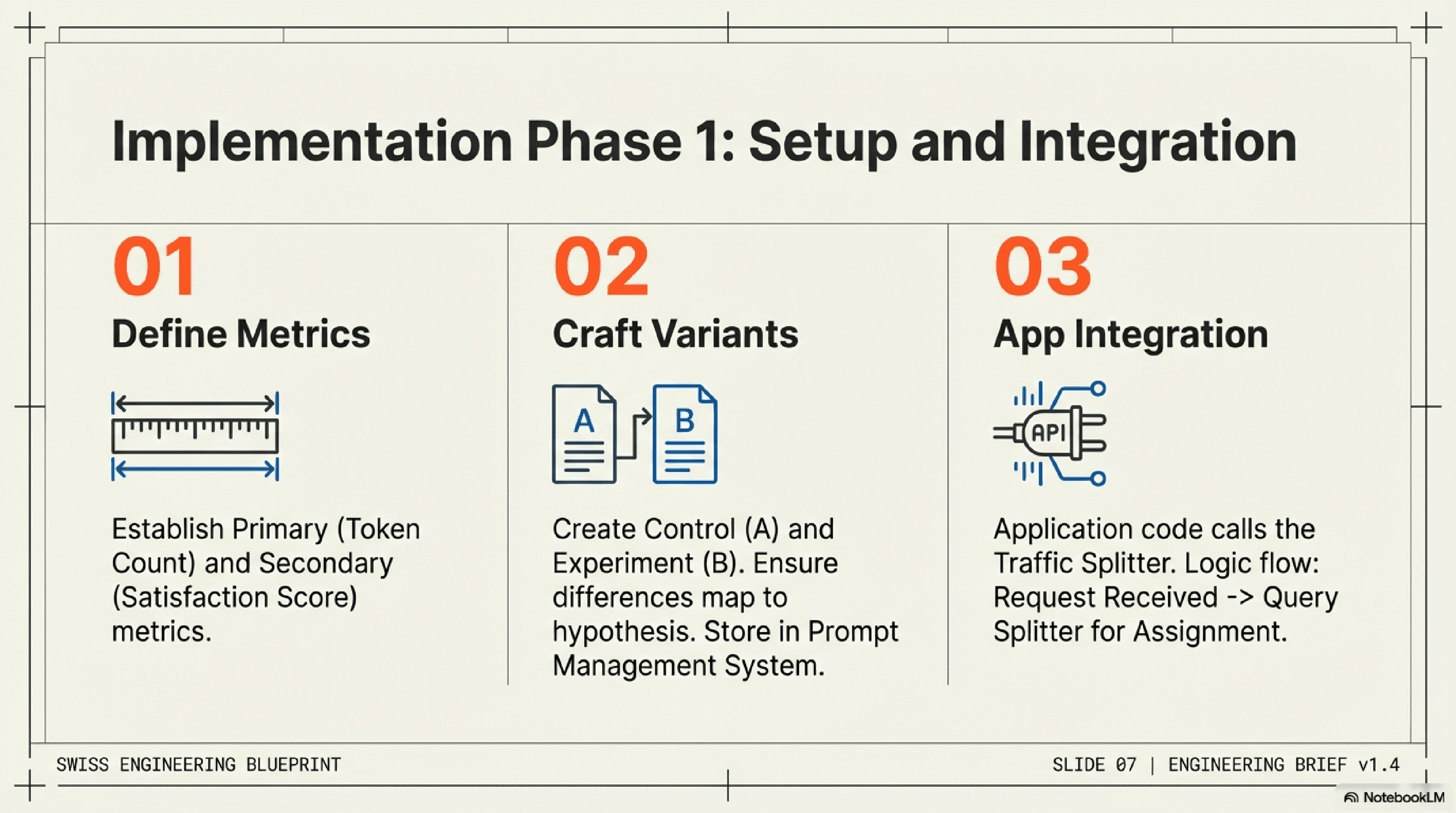
Define Your Hypothesis & Metrics: Before writing any code, clearly articulate what you're trying to achieve. Example Hypothesis: "Prompt B, which explicitly asks the LLM to 'be concise,' will reduce token usage by 15% without negatively impacting response quality, compared to Prompt A." Define your primary (e.g., token count) and secondary (e.g., user satisfaction score, coherence) metrics.
Craft Your Prompt Variants (A and B): Develop your control prompt (A) and one or more experimental prompts (B, C, etc.). Ensure the differences are specific and testable against your hypothesis. Use your prompt management system to store and version these.
Integrate with Your Application: Your application code needs to know which prompt to fetch for a given user or request. This involves calling your traffic splitter.
Implement Traffic Splitting:
When a request comes in, use your experimentation platform to assign the user/session to either "Prompt A" or "Prompt B" (e.g., 50/50 split).
Fetch the corresponding prompt variant from your prompt management system.
Pass this prompt to the LLM Integration Layer.
Log User Interactions and LLM Responses: This is crucial. For every LLM call, log:
The prompt variant used.
The full LLM input (including the prompt).
The full LLM output.
Any relevant metadata (timestamp, user ID, session ID, latency, token count).
Crucially, capture user feedback or downstream actions related to the LLM's response.
6. Analyze Results for Meaningful Prompt Evaluation: Once enough data is collected (ensuring statistical significance), use your analytics pipeline to compare the performance of Prompt A and Prompt B against your defined metrics. Look for statistically significant differences.
Tutorial Implementing Prompt A/B Tests in Production Python
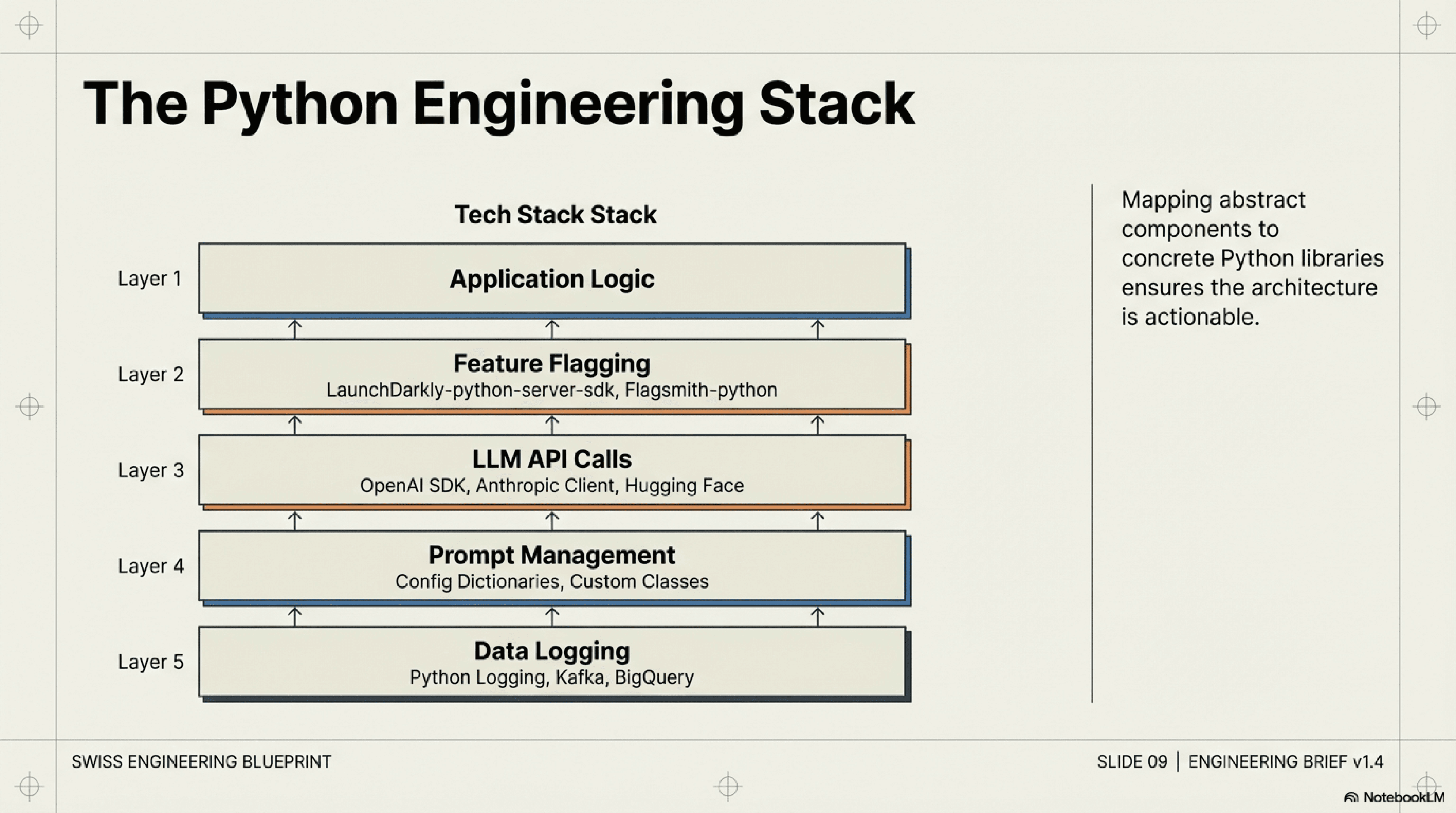
For engineers working in Python environments, integrating these components is straightforward. You can leverage existing Python libraries for:
Feature Flagging: Libraries like `LaunchDarkly-python-server-sdk` or `Flagsmith-python` can manage traffic splitting.
Prompt Management: Simple dictionary structures, configuration files, or even a database can store prompts. For more advanced needs, consider custom classes or dedicated prompt engineering frameworks.
LLM API Calls: The official client libraries for OpenAI, Anthropic, Hugging Face, etc., are all Python-based.
Data Logging: Standard Python logging, combined with data streaming tools like Kafka or direct writes to a data warehouse (e.g., BigQuery, Snowflake) via Python SDKs, can handle event capture.
The core logic would involve a function that takes a user ID, decides which prompt variant to use, constructs the full prompt, calls the LLM, and logs the outcome.
Hypothesis Formulation Checklist
Leveraging Open-Source and GitHub for Prompt A/B Testing
Many open-source projects and GitHub repositories offer valuable insights and components for building your LLM production testing framework. You can find:
Experimentation Platforms: Some companies open-source their internal A/B testing tools.
Prompt Engineering Tools: Projects dedicated to managing, versioning, and testing prompts.
Data Pipeline Examples: Reference architectures and code for collecting and processing large volumes of event data.
Searching GitHub for terms like "LLM experimentation framework," "prompt testing," or "A/B testing Python" can yield useful starting points and inspiration for your own implementation.
Key Metrics and Best Practices for Analyzing Prompt A/B Test Results
Successful prompt A/B testing production hinges on defining the right metrics and adhering to sound experimental practices.
Defining Success: What to Measure in LLM Production Testing
Metrics should align directly with your application's goals:
User Engagement: Clicks on "copy," "regenerate," or "thumbs up/down" buttons; time spent interacting with the LLM output; task completion rates.
Quality Metrics:
Human Evaluation: The gold standard. Have human reviewers rate responses based on relevance, coherence, helpfulness, safety, and conciseness.
Automated Metrics: While imperfect for LLMs, metrics like ROUGE, BLEU, or custom semantic similarity scores can provide proxy signals, especially for summarization or generation tasks.
Implicit Feedback: Number of edits by users, bounce rates, conversion rates.
Cost Efficiency: Average token usage per interaction, API call cost.
Latency: Average response time from the LLM.

Defining Success Metrics
Best Practices for Sustained Prompt Optimization
Statistical Significance: Don't declare a winner prematurely. Ensure you have enough data to draw statistically sound conclusions. Use A/B testing calculators to determine required sample sizes.
Isolate Variables: Test one major change at a time to clearly attribute performance differences to specific prompt modifications.
Continuous Monitoring: Even after deploying a "winning" prompt, continue to monitor its performance. LLM models can drift, and
Tags
#A/B Testing#Prompt Testing