A/B Testing Statistics Explained
How A/B testing combines split testing, multivariate analysis, and p-values for accurate results
Aryan Gupta
December 16, 2025

Modern teams rely on data rather than gut feelings to understand what users respond to. In the past, product decisions were often driven by strong opinions, which sometimes led to changes that delivered little impact. Experimentation has shifted this approach by giving teams a clear way to test ideas in real conditions and measure what actually performs better.
The idea is simple. Instead of guessing, you show different versions of a feature to different groups of users and compare how they behave. Whether the change is small, like a headline, or a full layout update, experiments reveal which version truly improves your metrics.
This reduces uncertainty and keeps decisions grounded in evidence. A/B testing, split testing, multivariate testing, and p values are the tools that make this possible. The next sections break down how each one supports better product decisions.
What is A/B Testing
A/B testing is a straightforward way to learn which version of a page or feature performs better with real users. You create two versions, the current version and a variant with one change, and split your audience so each group sees one version. By comparing their behaviour, you identify which version produces stronger results.
Its main strength is clarity. Since only one element changes at a time, any improvement can be directly linked to that change, whether it is a new headline or button text. This focused approach provides reliable insights and prevents teams from making changes that only seem effective in theory.
Successful A/B testing also requires clear goals. Teams must decide which metric matters most and collect data until the result is strong enough to trust. This mix of creativity and evidence makes A/B testing a key tool for confident product decisions.
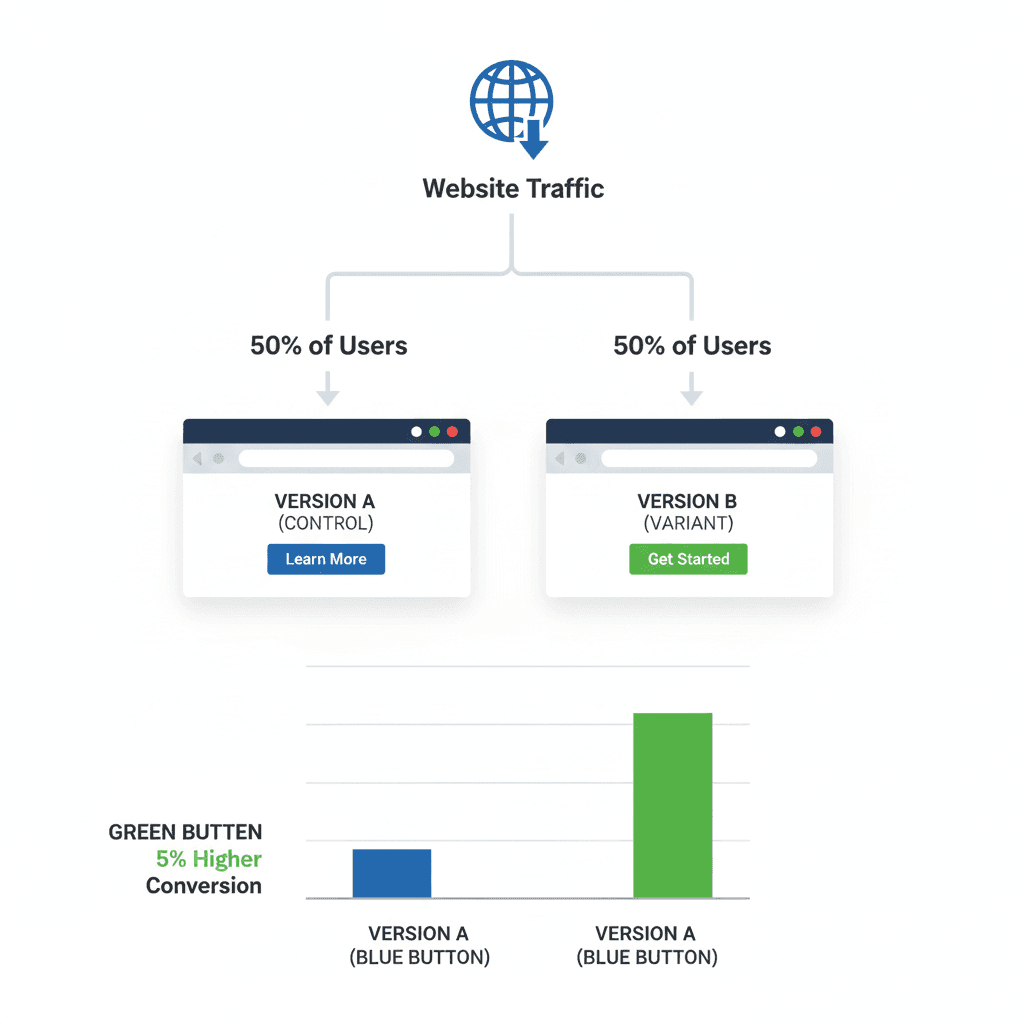
A/B testing example with control and variant
What is Split Testing and How It Differs from A/B Testing
Split testing is the method of dividing your audience into groups and showing each group a different version of a page or feature. While it is often used as another name for A/B testing, the idea is straightforward: you compare two or more versions to see which one performs better.
The focus of split testing is often on testing bigger, more noticeable changes between versions. Instead of adjusting one small element (like a button color), you might compare two entirely different page layouts, content structures, or even separate pricing pages. This allows you to explore broader design directions without worrying about individual components.
No matter how many versions you test, the goal stays the same. You measure real user behavior and use the results to decide which version leads to stronger outcomes.
Understanding Multivariate Testing
Multivariate testing is used to evaluate several elements of a page at the same time. Instead of comparing full versions as in an A/B test, you adjust individual components such as headlines, images, or buttons and create different combinations. Users see these combinations, and you measure which mix delivers the strongest results.
This method helps you understand how each element affects performance and how different elements work together. It reveals whether a headline is more effective with a certain layout or if a button style performs better with a specific image.
Because many variations run at once, multivariate testing requires more traffic so each combination receives enough data. For this reason, it works best on pages with steady or high user volume. When applied correctly, it provides deeper insight and helps teams refine designs with more confidence.

Multivariate testing example with multiple combinations
How to Choose Between A/B and Multivariate Tests
Choosing the right testing method depends on your goals and the amount of traffic you have. A/B testing works best when you want to test one clear change, such as a new headline or layout. It is simple to set up, needs less traffic, and gives quick, reliable results.
Multivariate testing is better when you want to analyse several elements at the same time. It helps you understand how different parts of a page work together, but it requires a larger audience so each combination gets enough data.
A simple way to decide is this. If you want a fast answer and have one idea to validate, use an A/B test. If your goal is to optimize multiple components and you have enough traffic, a multivariate test offers deeper insights.
A/B Testing for AI Prompts and LLM Workflows
A/B testing is no longer limited to pages, buttons, or interface changes. As more products rely on AI, teams now apply the same experimentation mindset to prompts and LLM workflows. The idea is similar, but instead of comparing two layouts, you compare two prompt versions, two system instructions, or even two different models to see which one produces more accurate and consistent responses.
Prompt wording plays a far bigger role than most people realise. A small change in phrasing can impact how an AI interprets the task, handles edge cases, or maintains tone. Running a prompt A/B test helps teams understand which variation delivers better results for their specific use case, whether that is support automation, content generation, or data extraction.
To evaluate AI tests, teams look at metrics such as clarity, correctness, reasoning quality, hallucination rate, latency, and overall cost. Tools like LaikaTest make this process easier by letting you run two or more prompt versions across multiple models, compare outputs, and see which configuration performs best. This brings structure to prompt design and removes guesswork, turning AI development into a measurable, repeatable workflow.
How P Values Strengthen Your Test Results
P values play an important role in deciding whether the results of an experiment are meaningful. Even when one version appears to perform better, the difference may be due to random variation. A p value helps you judge how confident you can be that the improvement is real.
In simple terms, a p value shows the likelihood that the difference between your test variations happened by chance. A lower p value means you can trust the result more. The most common threshold is p less than 0.05. This means there is less than a five percent chance that the observed difference is random, and a strong chance that the winning version truly performs better.
Think of the p value as the confidence score of your experiment. A low score signals strong evidence in favour of the winning variation. A high score suggests the result is not reliable enough to guide a decision. By checking the p value, teams avoid adopting changes that look promising at first but do not hold up when tested against real user behaviour.
These principles also apply when testing AI prompts. Instead of measuring clicks or conversions, you measure accuracy, clarity, or hallucination rate across multiple runs. A lower p value indicates that one prompt consistently produces stronger outputs, making it more reliable to use in production workflows.
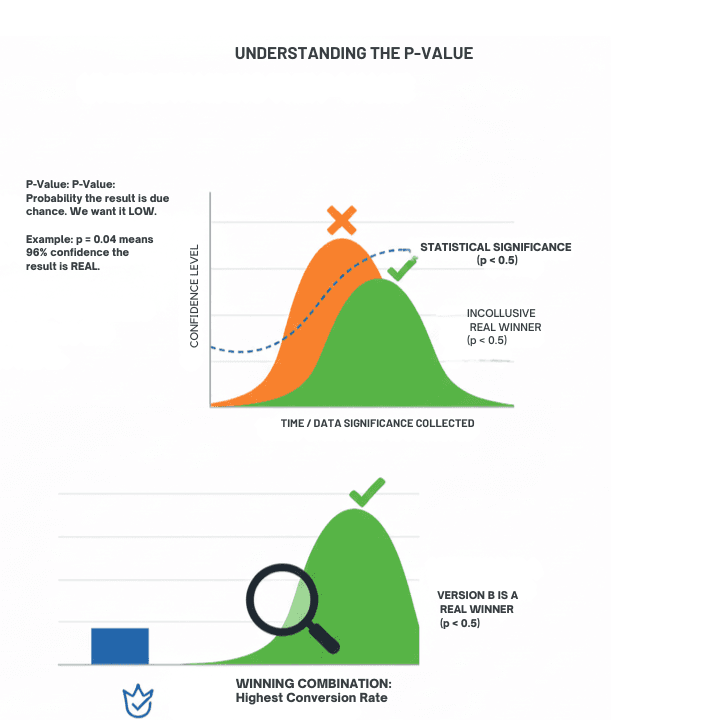
Visual understanding of p-value
Running Your First Test: A Simple 5 Step
1. Identify the problem: Define the specific issue you want to improve, such as low clicks or poor signup rates. A clear problem keeps the test focused.
2. Create a hypothesis: Write a simple statement of what you will change and why. This guides the direction of your test.
3. Build one clean variation: Change only one element, like a headline or call to action, so you can clearly see what caused the difference.
4. Split traffic fairly: Show Version A to one group and Version B to another. Let the test run until enough data is collected.
5. Review and apply the results: When the result is statistically reliable, choose the winning version. If no clear winner emerges, use the insights to plan the next test.
Conclusion
Successful experimentation is not only about running individual tests. It is about building a mindset that values evidence over assumptions and continuous learning over one time wins. A single A/B test can offer a useful insight, but long term growth comes from consistently testing ideas, understanding user behaviour, and using data to guide decisions.
This mindset encourages teams to stay curious, make small but thoughtful improvements, and view every result as a chance to learn something new. Not every variation will outperform the original, and that is expected. What matters is the discipline of testing, measuring, and applying insights with clarity.
When experimentation becomes part of the workflow, teams make decisions with more confidence and deliver changes that genuinely improve the user experience. This steady, evidence driven approach is what turns simple tests into meaningful product growth.
Tags
#A/B Testing#Split Testing#Multivariate Testing#p-values#Statistics